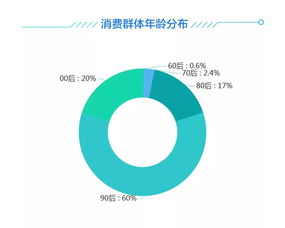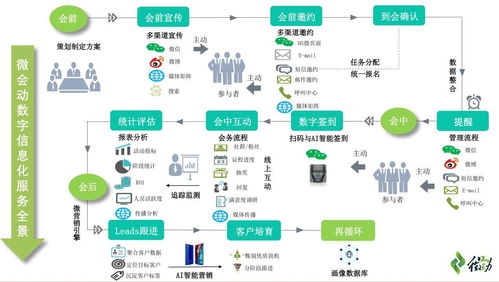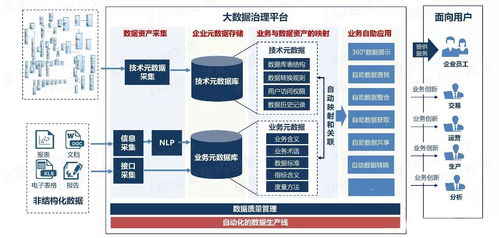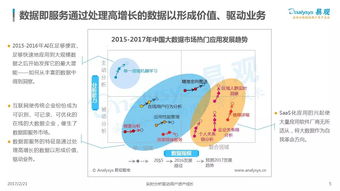
在当今数据驱动的时代,用户行为数据的实时处理与分析已成为众多互联网企业的核心竞争力。面对每日高达20亿条数据的处理挑战,构建一个高效、稳定、可扩展的实时用户行为服务系统至关重要。本文将深入探讨支撑如此庞大数据处理量的系统架构实践,涵盖从数据采集、传输、处理到存储与应用的全链路设计。
一、整体架构概览:分层解耦与流批一体
系统的核心设计思想是分层解耦与流批一体。整体架构自下而上可分为四层:
- 数据采集层:部署在客户端(Web/App)及服务器端的轻量级SDK,负责以高并发、低延迟的方式收集用户点击、浏览、搜索等原始行为事件,并通过HTTP/2或长连接将数据压缩后发送至网关。
- 数据接入与缓冲层:采用高性能API网关集群接收数据,并进行初步的校验、清洗与格式化。数据被写入高吞吐的分布式消息队列(如Kafka或Pulsar)作为统一的数据总线,起到削峰填谷和解耦生产与消费的作用,这是应对20亿日流量冲击的关键缓冲带。
- 实时计算层:这是系统的“大脑”。采用Flink或Spark Streaming作为流计算引擎,消费Kafka中的数据流。通过时间窗口、状态管理等机制,实时进行用户画像标签更新、异常行为检测、实时计数(如PV/UV)及复杂事件序列匹配。计算任务被拆分为多个相互独立的DAG(有向无环图),实现水平扩展。
- 存储与服务层:计算结果根据用途分流存储。实时更新的用户标签和画像存入Redis或Cassandra以供毫秒级查询;需要聚合分析的结果写入OLAP数据库(如ClickHouse或Druid);原始明细日志则存入HDFS或对象存储(如S3)供离线深度分析。对外提供统一的低延迟查询API服务。
二、核心技术实践与优化策略
- 数据压缩与序列化:在采集与传输阶段,采用Protocol Buffers或Avro等高效的二进制序列化协议,并结合Snappy或LZ4进行压缩,减少网络带宽消耗高达70%以上。
- 动态资源调度与弹性伸缩:计算层部署在Kubernetes集群上,利用其弹性伸缩能力。根据Kafka队列的堆积Lag指标,自动扩缩容Flink作业的TaskManager实例,实现计算资源的按需分配,在成本与效率间取得平衡。
- 精确一次(Exactly-Once)处理语义:在支付、积分等关键业务场景,通过Flink的检查点(Checkpoint)机制与Kafka事务性写入的结合,保证数据在端到端处理过程中不丢不重,确保数据准确性。
- 多租户与资源隔离:通过消息队列的Topic划分、计算作业的队列优先级调度,以及存储层的命名空间隔离,实现不同业务线或产品线的数据与资源隔离,避免相互干扰。
- 全链路监控与告警:构建从数据采集埋点上报量、网关接收延迟、Kafka堆积量、Flink作业背压到API服务P99延时的全方位监控仪表盘。设置智能告警,确保问题能在影响业务前被及时发现与定位。
三、挑战与应对
- 数据倾斜:某些热门商品或用户可能产生海量行为,导致计算任务负载不均。应对策略包括在Flink中采用预聚合、在KeyBy前加盐散列,或使用本地窗口聚合后再进行全局合并。
- 高峰流量冲击:在促销活动期间,流量可能瞬间激增数倍。系统依赖消息队列的持久化能力缓冲压力,并通过事前对计算和存储资源进行预案扩容,以及流计算作业的优化(如增大并行度、调整窗口大小)来平稳度过高峰。
- 时效性与准确性的权衡:完全实时的处理对资源消耗极大。对于部分可接受分钟级延迟的统计指标,可采用微批处理(如Flink的Mini-Batch)或Lambda架构,用离线批量作业的结果定期修正实时结果,在保证大体实时性的同时提升成本效益与最终准确性。
日处理20亿条用户行为数据的实时系统,是一个对架构设计、技术选型和运维能力要求极高的综合性工程。其成功的关键在于构建一个各层可独立扩展、具备强大缓冲能力和容错性的流水线。通过将流批一体、弹性伸缩、精确一次处理等现代大数据技术深度整合,并辅以细致的监控与优化,企业能够将海量、无序的实时数据流,转化为驱动产品智能迭代、运营精准决策和用户体验提升的宝贵资产。随着实时数仓、数据湖等概念的进一步融合,此类系统的边界和能力将持续拓展。